If you don’t collect data, it’s not really research: how the primacy of “primary data” is hampering mental health science in India
 Photo by Subhash Nusetti on Unsplash
Photo by Subhash Nusetti on UnsplashTable of Contents
India is home to almost 1.5 billion people – nearly a fifth of the world’s population and more than that of Europe and North America combined 1. An estimated 197 million people in the country live with mental illness, and this number is growing 2. India also houses a substantial mental health research workforce, with a demonstrated record of leading research output across low- and middle-income countries 3. We estimate that between 2,000-4,000 articles on mental health originate in India annually 4, and upwards of 30,000 dissertations are generated every year in psychology alone 5. Yet, despite this volume, India lacks answers to fundamental questions about its population’s mental health: How is the treatment gap for common mental health disorders changing? What social and environmental factors are the strongest contributors to poor mental health? What impact do various policy initiatives have?
We propose that one significant reason is a systemic bottleneck: the overreliance of Indian mental health research on primary data collection, and the corresponding neglect of secondary data. The result is a research ecosystem dominated by large-scale clinical trials, small-sample interventional studies, and cross-sectional surveys built on convenience samples that overrepresent urban populations 6. Of the 47 early-career researchers (ECRs) we surveyed in a rapid poll, only 3 reported the use of any secondary data in their dissertations 7.
This is a particular problem because many questions India needs to answer involve variables like caste, gender, poverty, heatwaves and violence exposure that cannot be ethically or practically manipulated in randomized controlled trials. Answering them requires large, longitudinal datasets, of which India has few. The Atlas of Longitudinal Datasets (2024) 8 identified only 51 health-related longitudinal datasets in India, compared to 1061 in Europe – a nearly 21x differential for a region with half of India’s population. Of those 51, mental health data were absent in nearly half, and most others had large barriers to data access.
However, the availability of data is growing. In recent years, significant effort and funding have gone into generating large, longitudinal datasets and the publishing of government-owned shareable data in India 9. Yet, availability has not translated into uptake – even freely-available datasets, such as the Young Lives dataset and UDAYA dataset 8 remain under-analysed. The National Mental Health Survey (NMHS) series 10, which accesses a representative sample from all of India’s states and union territories, is one of India’s best resources. Yet, despite completing postgraduate training at the same institution it’s hosted at, we cannot recall anyone suggesting or discussing accessing its data as a possibility for our dissertations. One of us can recount distinct instances of proposals for secondary analysis of other data being shot down. Reasons for dismissal ranged from it being “too complex” or “unconventional for our field” to the concern that it would deprive students of the experience of collecting data themselves. This reflects a system where secondary analysis has not yet taken root as a research practice and we are left with datasets built at considerable public cost being chronically underused.
This orientation towards primary data is not only inefficient but also self-undermining: it generates redundancies and compounds burden on researchers and participants alike. Researchers report persistent struggles in recruiting participants 11, while participants, especially those from vulnerable communities, report fatigue 12. In a recent lecture we gave, one student shared how a sanitation worker expressed frustration at being repeatedly approached for research in ways that yielded little tangible change 13. While there is no doubt about the need for high-quality primary data, especially from underrepresented communities, our concern is with repetitive, high-effort studies that result in little moving of the needle on evidence-informed mental health policy. Many of these studies are too small to be conclusive and there is less synthesis of existing evidence, leaving policy and intervention reliant on Western evidence 14.
The vicious cycle of the “primacy of primary data” bottleneck
We argue that this bottleneck persists because of systemic disincentives operating at three interlocking levels: epistemic norms, training, and funding incentives. Epistemically, the norm that primary data = ‘real’ research is rarely formally documented but is enforced pervasively through curricula, departmental culture, and funding language. The skeptical reactions we described above to secondary analysis are not fringe reactions – they reflect a research ecosystem in which doing research and collecting data are deeply intertwined and almost equated. At the level of training, popular programmes that produce mental health researchers (e.g., psychology and psychiatry) introduce but rarely provide substantive preparation in epidemiology, biostatistics, and large-scale data management. Coupled with the lack of a culture of interdisciplinary collaboration, the capacity to use existing data, even when available, is severely constrained. At the level of funding, major domestic funding bodies (Indian Council for Medical Research (ICMR), Department of Biotechnology) have few dedicated calls for secondary analysis of mental health data. Funding agencies frequently emphasize ‘novelty’ and ‘innovation’, criteria that are often implicitly equated with the collection of new data. Notably, while agencies sometimes issue specific calls for secondary data analysis in health domains, mental health is not on this list.
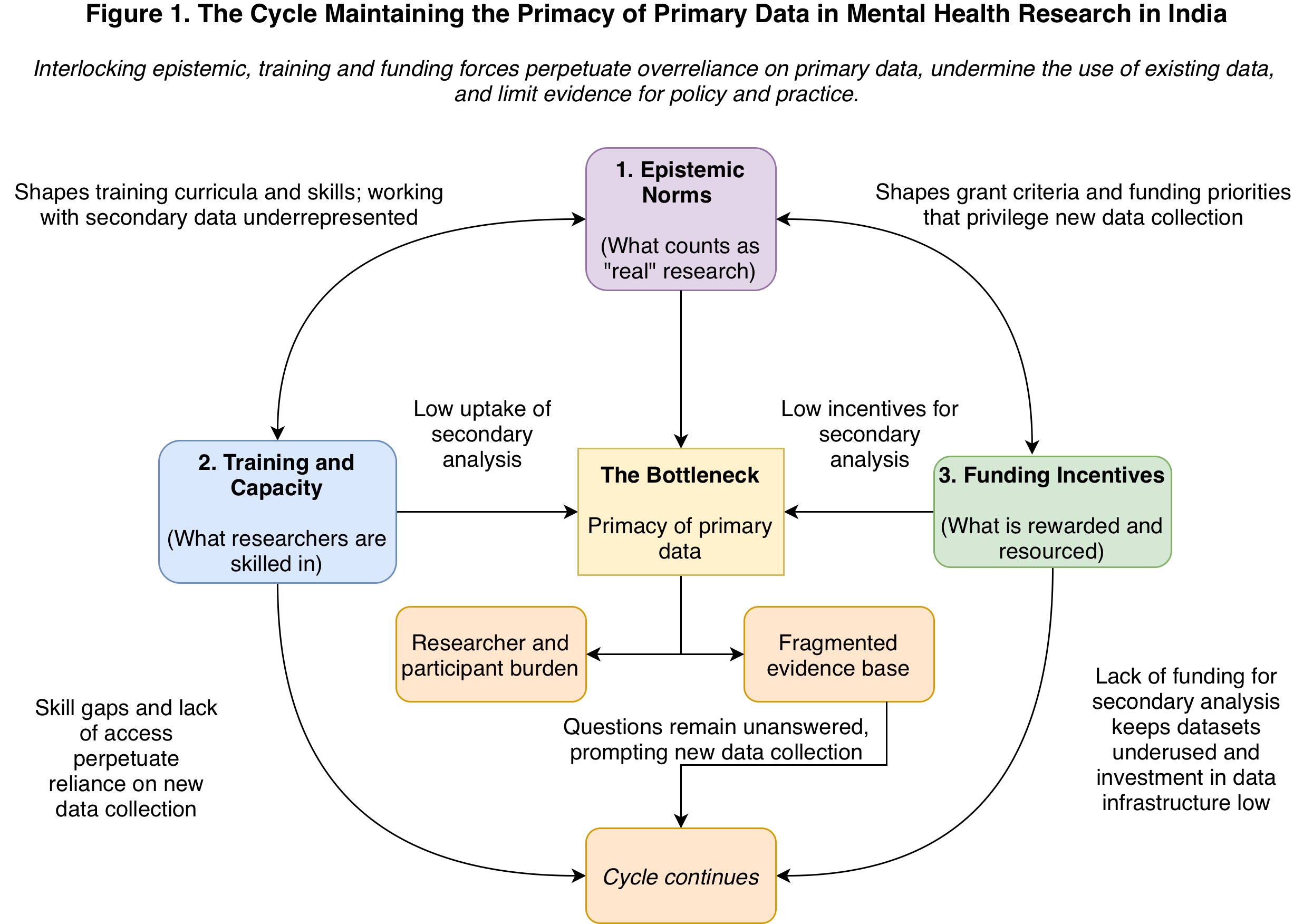
Figure 1 shows the cycle we believe this creates. The fragmented evidence base generated reinforces the need for more data collection. No individual actor or small group is positioned to escape this system, and the cycle continues across generations of researchers.
So, what do we do now?
In our proposed solution, we focus on a training pathway for early-career researchers because, in our experience, ECRs are the “bottom of the pyramid”: forming the majority of the research workforce and the ones driving change in the system, especially as they move upwards through it. This model borrows from the experience of the open science movement, which has largely been driven by ECRs 15. Our hypothesis is that setting up a training pathway for ECRs in accessing, using and sharing data will lead to more research outputs using secondary data, more favorable attitudes towards secondary data amongst faculty and students, more skills in using secondary data, and less researcher burden.
As an experiment, we propose testing this training pathway at an Indian institution offering Master’s degrees in psychology 16. This pilot program should have three main components. First, it should teach students how to find and access relevant data, including disseminating existing sources of data, such as the ICMR data repository. Second, it should teach basic skills to work with such data, including what kinds of research questions can be answered and initial paths to answering them (e.g., introduction to causal inference methods). Third, it should teach students how to share their own data in an ethical and secure manner.
In addition to didactic teaching, this training should create spaces for coordination of data collection with other students (e.g., by setting up “speed dating” where students can discuss potential ideas with each other and form teams) as well as for collaboration with departments such as statistics and epidemiology who tend to use secondary data more. Having the buy-in of senior faculty through involving them in delivering the training, supporting them with supervision of such dissertations and addressing any concerns they have will be crucial. This training should be offered at the beginning of the academic year, so students have time to incorporate this into their dissertations.
To measure intervention efficacy, our primary outcome will be the number of student dissertations that employ secondary data in part or fully. Our secondary outcomes will be surveys and interviews measuring attitudes and skills in use of secondary data, researcher burden, as well as research outputs using secondary data (e.g., peer-reviewed publications) in the next two years from that institutional department overall.
We propose that two cohorts of students enrolled in a particular Master’s program at the same institution be compared to each other, the first (senior) cohort is the control group and the second (junior) cohort receives the training. Primary and secondary outcomes should be measured at the start and end of the academic year for both cohorts. This is a “natural experiment” design. If two consecutive cohorts are compared, we believe that possible confounders such as socio-demographic differences in the cohorts, teaching curriculum and style differences, differences in student ability and motivation and differences in institution-level secular trends are likely to be minimal. Further, key confounders can be carefully measured at baseline and adjusted for in analyses.
This is one proposed solution that would leverage the existing infrastructure at an institution and test whether integrating this training pathway as part of overall training for mental health researchers can be effective. However, another idea might be to set up this training pathway as a competitive fellowship welcoming individuals from all disciplines, which would then select individuals with high interest and motivation to use secondary data. There are also other possible interventions, which may be needed in combination with training pathways, like:
Setting up local institution-level repositories for researchers to securely and safely share and access data. Institution-level solutions are likely to have more buy-in from various stakeholders (e.g., ethics boards, faculty members) and may be more acceptable to research participants. They are also likely to be easier to govern as a local manager can be appointed to provide training and answer questions.
Indian funding agencies should put out calls specifically for secondary analysis of existing mental health data. One model may be a competition for researchers to answer a specified, urgent research question using existing data.
A call to action: for the mental health and metascience community
The urgency to address this bottleneck is considerable. Globally, mental health science is moving towards large-scale secondary data, linked administrative records, biobanks, and machine-learning-enabled analysis to inform policy and intervention. Countries that have invested in data infrastructure can generate evidence at a scale and efficiency difficult to replicate through primary data alone. India risks arriving at this table too late, not for want of researchers, but because it has not yet built a research culture that treats existing data as a serious site for discovery.
This is also a concern of epistemic equity. India’s population, diversity, and mental health burden are increasingly studied by researchers based in high-income countries with greater access to analytical tools, funding, and data ecosystems. Without capacity and incentives to analyse Indian data, we risk becoming a site of data extraction rather than knowledge production. For the first time, however, the mental health data landscape in India is shifting. The National Family Health Survey-5 included mental health modules at a national scale; the Ayushman Bharat Digital Mission is beginning to generate population-level administrative health records; and the results of the National Mental Health Survey-2 are expected soon. This is a rare convergence of need, opportunity and capacity.
Our call to action is therefore twofold. To metascience, first, we appeal for greater emphasis on context in research systems. Prescriptions for “better science” cannot be imported wholesale from high-income settings where data infrastructures, funding systems, publication incentives, and institutional histories differ sharply. To the Indian mental health research ecosystem, we appeal that secondary data must no longer be treated as a lesser form of research. Training programmes, funders, ethics boards, journals, and institutions must actively support data reuse, linkage, replication, synthesis, and responsible sharing. Primary data will remain essential, but it should be collected when it is genuinely needed, designed for reuse where possible and situated within a cumulative evidence ecosystem. We invite this realignment so that we can better answer pressing questions that remain unanswered – where needs are urgent, change is rapid, and the scales are massive.
Acknowledgements: We thank Praveetha Patalay for comments on an earlier version of this essay.
AI Disclosure Statement: We used generative AI tools (Claude Sonnet 4.6, ChatGPT 5.5, Gemini 3.1 Pro) for a) copyediting of draft text, b) conducting research for funding calls in India and c) generating the initial design iteration for figure 1, based on our writeup of the proposed cycle. All final arguments and conclusions are our own, and we take responsibility for all output in this essay.
Worldometer data: India population, Europe and North America population ↩︎
Sagar, R., Dandona, R., Gururaj, G., Dhaliwal, R. S., Singh, A., Ferrari, A., Dua, T., Ganguli, A., Varghese, M., Chakma, J. K., Kumar, G. A., Shaji, K. S., Ambekar, A., Rangaswamy, T., Vijayakumar, L., Agarwal, V., Krishnankutty, R. P., Bhatia, R., Charlson, F., … Dandona, L. (2020). The burden of mental disorders across the states of India: The Global Burden of Disease Study 1990–2017. The Lancet Psychiatry, 7(2), 148–161. Link ↩︎
Razzouk, D., Sharan, P., Gallo, C., Gureje, O., Lamberte, E. E., De Jesus Mari, J., Mazzotti, G., Patel, V., Swartz, L., Olifson, S., Levav, I., De Francisco, A., & Saxena, S. (2010). Scarcity and inequity of mental health research resources in low-and-middle income countries: A global survey. Health Policy, 94(3), 211–220. Link ↩︎
This estimate synthesizes output across clinical and social science disciplines. A baseline search of PubMed (2019-2024) for mental health and psychiatry keywords ((“Mental Disorders”[Mesh] OR “Mental Health”[Mesh] OR “Psychiatry”[Mesh] OR “Psychology”[Mesh] OR “mental health”[Title/Abstract] OR psychiatry[Title/Abstract] OR psychology[Title/Abstract]) AND (India[Affiliation] OR India[ad]) AND (2019:2024[Date - Publication])) affiliated with India yielded an average of over 1,500 clinical publications annually, representing approximately 25% of the global biomedical output for the same search parameters (same search terms, no affiliation/ad). When accounting for the vast body of psychological, sociological, and public health research published in regional and non-MEDLINE indexed social science journals, the total annual volume is conservatively estimated between 2,000 and 4,000 articles. ↩︎
This estimate is extrapolated from the All India Survey on Higher Education (AISHE) 2021-2022 data. While psychology data is not clearly delineated, we used the available categories to conservatively estimate that approximately 69,000 undergraduate, 57,000 postgraduate, and 1,300 doctoral students are enrolled in psychology programs. Assuming these student numbers are spread out across 3, 2 and 5 years respectively (as average completion times for these programs) and assuming near-universal research project mandates for final-year postgraduates and doctoral candidates, alongside 1/5th of final-year undergraduates, the annual output of student research exceeds 30,000 dissertations. ↩︎
This statement emerges from a combination of our lived experience as researchers in the Indian mental health research ecosystem, conversations with colleagues and reviewing evidence of registered studies on Clinical Trials Registry - India, where both larger clinical trials and smaller observational studies are recorded. For example, an interested reader can use “Advanced search” and search for studies with “mental health” in the “health condition/problem studied” to get one slice of ongoing mental health research in India. ↩︎
We used a convenience sample here ourselves, asking our own MPhil Clinical Psychology cohorts of 20 and 27 students respectively, whether they had used secondary data in their MPhil dissertations. ↩︎
Atlas of Longitudinal Datasets. (2024). Atlas of longitudinal datasets. Retrieved April 1, 2026 from Link ↩︎ ↩︎
Gururaj, G., Varghese, M., Benegal, V., Rao, G. N., Pathak, K., Singh, L. K., Mehta, R. Y., Ram, D., Shibukumar, T. M., Kokane, A., Lenin Singh, R. K., Chavan, B. S., Sharma, P., Ramasubramanian, C., Dalal, P. K., Saha, P. K., Deuri, S. P., Giri, A. K., Kavishvar, A. B., . . . NMHS Collaborators Group. (2016). National mental health survey of India, 2015–16: Summary (NIMHANS Publication No. 128). National Institute of Mental Health and Neuro Sciences Website ↩︎
Leeper, T. J. (2019). Where Have the Respondents Gone? Perhaps We Ate Them All. Public Opinion Quarterly, 83(S1), 280–288. Link ↩︎
Ghafourifard, M. (2024). Survey Fatigue in Questionnaire Based Research: The Issues and Solutions. Journal of Caring Sciences, 13(4), 214–215. Link ↩︎
This point is also made in this paper: Cleary, M., Siegfried, N., Escott, P., & Walter, G. (2016). Super Research or Super-Researched?: When Enough is Enough…. Issues in Mental Health Nursing, 37(5), 380–382. Link ↩︎
Rajwar, E., Pundir, P., Parsekar, S. S., D S, A., D’Souza, S. R. B., Nayak, B. S., Noronha, J. A., D’Souza, P., & Oliver, S. (2023). The utilization of systematic review evidence in formulating India’s National Health Programme guidelines between 2007 and 2021. Health Policy and Planning, 38(4), 435–453. Link ↩︎
Toribio-Flórez, D., Anneser, L., deOliveira-Lopes, F. N., Pallandt, M., Tunn, I., Windel, H., & on behalf of Max Planck PhDnet Open Science Group. (2021). Where Do Early Career Researchers Stand on Open Science Practices? A Survey Within the Max Planck Society. Frontiers in Research Metrics and Analytics, 5, 586992. Link ↩︎
While we recognise that PhD students may be more likely to continue in research careers and hence may be a better target population for our training, the variable timelines of PhD degrees and typically small numbers of PhD students at a particular institution makes it difficult to conduct a controlled experiment to test our hypothesis. ↩︎

